

最終更新日: 2025年1月29日
少し前にComputer Useというというものが出ました。これは仮想のブラウザを生成AIが操作することで自動で作業を行うというものです。
とは言っても自分の環境ではないため、速度ももっさり、スクショも取るので料金もすごく高い。ということでした。以下をご確認ください。
そこで実際にローカル上のブラウザを動かしてしまおうというのがBrowser Useです。Computer Useの場合にはClaude専用の技術だったのでそこをほかのLLMでも使えるように。というところもポイントです。
ただ、操作するのにコードがいたのでそれではものたりないのでその操作画面にUIをつけちゃおうというのが「Browser Use WebUI」です。
これをWindows環境下で使えるようにしていくのをできるだけ簡単にできるように解説していければと思います。
この記事でわかること
・Browser Use WebUIをwindows上で動かすことができるようになる
コンテンツ
Browser Use WebUIとは?

まずいきなりWebUIなので混乱しますが、先ほどの説明の通り前提にBrowser-Useというものがあります。
これはCLIで(黒い画面で)コマンドを打って操作するというものです。その裏の技術としてはplaywright(プレイライト)というスクレイピング用ツールが使われています。
playwrightとは?
このplaywrightなんかアイコンが毒々しい(笑)のであれですが、あのMicrosoft によって開発され、2020 年 1 月 31 日にリリースされた、ブラウザテストと Web スクレイピング用のオープンソースの自動化ライブラリです。
そこそこ最近出てきたもので、以前はテスト自動化といえば「Selenium」だったのですが、そこにplaywrightに加わったような感じです。ただ今でもSeleniumの方がどちらかといえば主流かもしれません。
で先ほども申し上げた通り、今回のBrowser-Useをもとに操作もブラウザからできるようにしたものが「Browser Use WebUI」です。なので、基本的に「Browser Use WebUI」というのは進化したBrowser-Useと現状では把握しておけばOKです。
結論、Browser-UseとBrowser Use WebUIは別物です。現状だと記事が少ないため混在していますが、多くの人が操作したいのはWebUIだと思うので今回はWebUIの方の解説です。
GitHubhttps://github.com/browser-use/web-ui
こちらがそのBrowser Use WebUIです。ここにもこのように書かれています。
このプロジェクトは、AI エージェントが Web サイトにアクセスできるように設計されたbrowser-useの基盤の上に構築されています。
このプロジェクトに貢献してくれたWarmShao氏に正式に感謝の意を表したいと思います。
Browser Use WebUIインストール方法
では以下の手順で、上記のhttps://github.com/browser-use/web-uiのプロジェクトをゼロからインストールして動作確認する方法を説明していきます。
今回はDockerを使わず仮想環境を作りそこにインストールしていくシンプルな方法を説明します。
1. Pythonがインストールされていることを確認
https://www.python.org/downloads
このURLよりインストールできます。特にバージョンとかわからない方はこの記事段階最新の3.13で動きますので、最新を入れましょう。
バージョンを気にする理由は古いものだと逆に最新だと動かないものがあるからです。
このインストール時に「Add Python to PATH」のオプションにチェックを入れることをお勧めします。
- Python 3.9以上をインストールしてください。
- PowerShellで以下を実行すれば現状バージョンを確認できます(任意)
python --version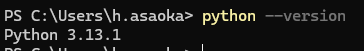
2. 新しい仮想環境を作成
プロジェクト用の仮想環境を作成し、環境を隔離します。
仮想環境とは別のフォルダを作ることでほかに影響を与えないするためのものぐらいに思ってください。
windowsのフォルダ位置でいうと
Cドライブ→ユーザー→自分のPCの名前→myenvという感じで作られます。
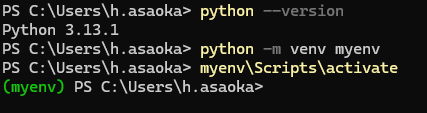
python -m venv myenv仮想環境を有効化:
myenv\Scripts\activate
仮想環境が有効になっていれば、PowerShellプロンプトが (myenv) に変わります。こんな感じです。
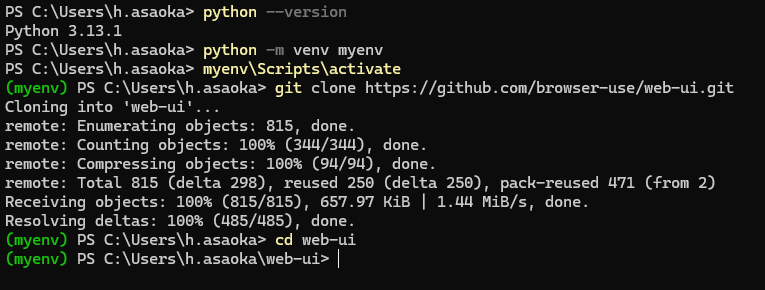
3. Gitリポジトリをクローン
指定のリポジトリをローカルにダウンロードします。そしてそのフォルダに入ります(cd web-ui)
git clone https://github.com/browser-use/web-ui.git
cd web-ui
4. 依存関係をインストール
リポジトリ内の requirements.txt に記載されている依存関係をインストールします。
pip install -r requirements.txt入力すると長いので少し待つとこんな感じになるかと。このようになるまで待ちます。

5. 環境変数を設定
続いて利用するには生成AIのAPIキーが必要です。.env ファイルにAPIキーや設定を記載する必要があります。必要に応じて取得してください。
その前に.envというファイルを作るためのコマンドを打ちます。
cp .env.example .env

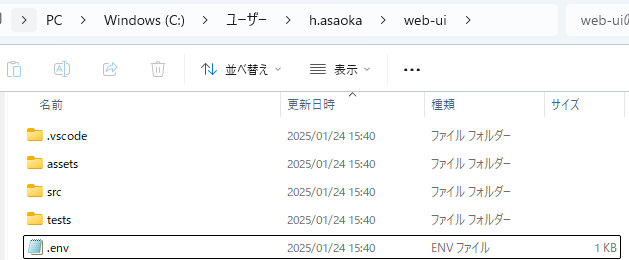
上記のような感じになると思います。これを開きます。メモ帳とかOKです。
OPENAI_ENDPOINT=https://api.openai.com/v1
OPENAI_API_KEY=
ANTHROPIC_API_KEY=
GOOGLE_API_KEY=
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_KEY=
DEEPSEEK_ENDPOINT=https://api.deepseek.com
DEEPSEEK_API_KEY=
# Set to false to disable anonymized telemetry
ANONYMIZED_TELEMETRY=true
# LogLevel: Set to debug to enable verbose logging, set to result to get results only. Available: result | debug | info
BROWSER_USE_LOGGING_LEVEL=info
# Chrome settings
CHROME_PATH=
CHROME_USER_DATA=
CHROME_DEBUGGING_PORT=9222
CHROME_DEBUGGING_HOST=localhost
CHROME_PERSISTENT_SESSION=false # Set to true to keep browser open between AI tasks
# Display settings
RESOLUTION=1920x1080x24 # Format: WIDTHxHEIGHTxDEPTH
RESOLUTION_WIDTH=1920 # Width in pixels
RESOLUTION_HEIGHT=1080 # Height in pixels
# VNC settings
VNC_PASSWORD=youvncpassword
これのOPENAI_API_KEYとかANTHROPIC_API_KEY=とかにAPIキーを入れます。そして保存します。
6. アプリケーションを起動
これで準備完了です。リポジトリの使用法によりますが、以下のようなコマンドでアプリケーションを起動します。
python -m webui
これでhttp://127.0.0.1:7788にアクセスすればOKです。Ctrlをおしながらアドレスの上をクリックしてもブラウザが開きます。
7. 動作確認
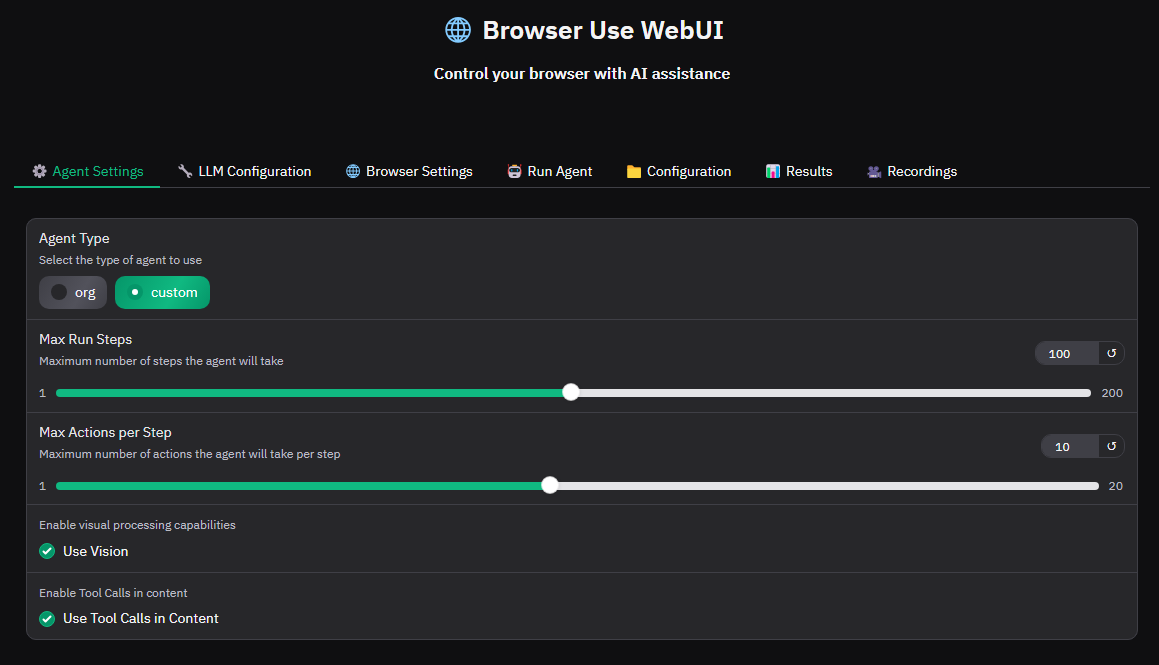
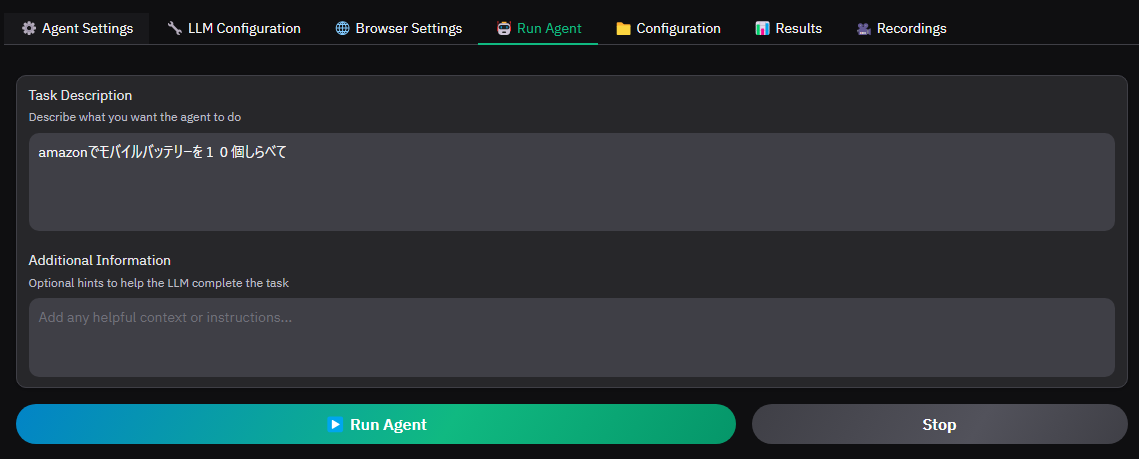
どうでしょうか?開きましたでしょうか。あとはLLM Configurationで希望のLLMに変えたりしてRun Agentの上の段のTask Descriptionにしてもらいたいことを入力してRun Agentをすることで動きます。
APIキーがまちがっていたり入力できていないと、先ほどまで操作していたPowerShellが以下みたいになります。

結果はResultsに残ります。操作していたときの動画も自動で残ります。ダウンロードも可能です。以下がその動画です。元が2分30秒あるので長すぎるので4倍速にしました。ちなみに今回は「gemini-2.0-flash-exp」を使ってます。
8. プロジェクトの止め方
プログラムの止め方です。黒い画面の上でCtrl+Cを押してください。以下のようになればOKです。

9. 次の使うとき
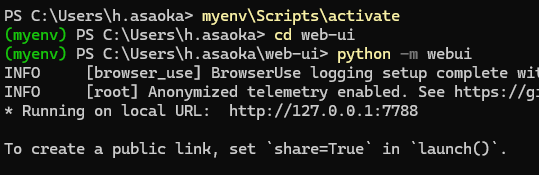
次に起動するときはPowerShellを開いて以下の通りです。
仮想環境を有効化する: プロジェクトフォルダがあるディレクトリで以下を実行
myenv\Scripts\activateプロジェクトフォルダに移動する: web-ui フォルダ内に移動します
cd web-uiプロジェクトを起動する
python -m webui戻ってしまっていると思うので上三つを入力してください。画像のようになればOKです。
10. プロジェクトの消し方
もう使わないよ!という時です。
Remove-Item -Recurse -Force myenv
Remove-Item -Recurse -Force web-uiこの二つを実行するか自分でフォルダにいってフォルダの手で消します。場所は先ほど記載した
「Cドライブ→ユーザー→自分のPCの名前」という中にあります。先ほどのコマンドはこれと同じことをしているだけです。この二つのフォルダを消してください。

Pythonとかは別にあってもいい気もするのでそれはそのままでもOKです。
Browser-Useの使いみちについて考える
Browser-Useの使いみちを考えたのですが、コスト対比としてはるかにComputer Useと比べれば料金も安いんですが、決まった繰り返す提携作業ならそれこそスクレイピング操作でいいのであれば一回コードを書けばコストかからないのでそっちでいいのでは?と思ってしまいます。
自由に動かすのにLLMの範疇でしか動かないといえば動かないのと複雑なことをするならプログラムを組むコード自体をLLMに書いてもらう。そっちの方がどこか合理的さを感じます。
悪いことを考えるのであればSNS自動運用とかですがそもそもSNSの自動運用は規約違反です。Xの場合には以下の通りです。
自動化機能の無断使用: Xの開発者ポリシーに準拠していない自動化またはスクリプト化されたアカウント。利用者が自らのアカウントへのアクセスまたは使用を許可したサードパーティーアプリケーションに関する責任は、最終的に利用者ご本人が負うことになりますのでご注意ください。
https://help.x.com/ja/rules-and-policies/authenticity
APIを使った正式なBOTアカウントならOKですが、準拠していないものはダメという内容です。
これだとCursor(とかWindsurf) & Roo Code(とかCline)とかで無双した方がエディタに慣れてる方であれば、現状だと早いし正確、自由度も高い。という感じです。
あとはDifyとかのワークフロー作ってくれないかな?とか、Googleのスライド作ってくれないかな?とかは思いました。ただComputer Useと違うのはスクショをとってるわけでなく、スクレイピングが元なので、要素に対して入力してるだけなので何ともいえない感じになりました。
まとめ
例えば製品化し、インストールも簡単。コストも安い、といったパッケージ型になればエンドユーザー利用は進むと思います。
と言ってるさなかに今日1/24にOpenAIがエージェント機能を発表してきたので(まだこの記事時点では日本ではつかえませんが)それが先日のWindowsアプリと統合されればそれも見えてくると思います。
ビジュアル的にうごいてくれるのはすごいワクワク!しますし、動いてる!って感じは、すごい楽しいですけどね!
ここの技術の安定化進む過程に必要なこととして
・料金とLLMの精度とのバランス
・インストール過程の簡単さ
・操作可能範囲
ここら辺を解消されれば一般化するのも時間の問題だなという印象です。


資料
ダウンロード
マスタデータのメンテナンスに関わる機能をまとめたSaaS「SMOOZ」
SMOOZはリレーショナルデータベースの課題を解決するサービスです。
オンラインデモで気軽に試すことが可能です。