

最終更新日: 2025年3月5日
DeepSeekの影響でローカルLLMが気になった人も多いのではないのでしょうか。

ローカルLLMとは自身の環境上に生成AIモデルをダウンロードしてWEB環境をつかわずに生成AIを活用する方法です。いままで生成AIを使おうとするのはブラウザから利用するというのが主流でした。
ただそうなるとモデルプロバイダー側に情報を入力する必要があり、またインターネットから遮断された環境では利用できないケースがほとんどです。
そこを自身のPCに内にLLMをダウンロードすることでいつでも制限なく利用できるようにするのがローカルLLMです。実際に簡単にチャットできるまでの初歩的な内容ではありますが操作の仕方を細かく解説していきます。
注意!!!
特段危険なことをするわけではないですが、個人で利用するなら自己責任なのでOKです。
ただし、もしも会社のPCで行おうとしているのであれば規模によるかとは思いますが、必ず情報システム担当者に訪ねてからご利用して下さい。会社や組織によっては利用を制限しているケースもあります。
この記事でわかること
・Ollamaを使って生成AIと会話することができる
コンテンツ
ローカルLLM
まずローカルLLMで代表的なものを挙げてみましょう。
DeepSeek R1
話題の中国オープンウェイトLLM。DeepSeek R1はOpenAI o1に匹敵するとも言われている。
gemma2
Geminiをもとに設計されたGoogleのLLM
llama3.3
Metaによる小型なLLM
phi4
大規模言語モデル(LLM)ならぬ小規模言語モデル(SLM)。Microsoft
アリババが作ったQwenとか上げだすときりがないのですが、ここら辺がメジャーどころです。ほかにもmistralとかもあるのですが。
これをもとに改良したモデルを個人が作っていたりなどしている感じです。
やはり料金を払い利用するClaudeやOpenAIのクローズドモデルを利用した方が精度の観点では高いことがほとんどです。
ローカルLLMを実際に導入してみよう
今回はOllamaというツールを使います。その他LM Studioといったツールのが方がよりクリック操作のみでりようできますが、のちにClineやRoo-codeなどのエージェントツールとつなぐこともやってみます。
なおDockerを使う方法もありますが今回はシンプルに使わずに行う方法です。
1.Ollamaのインストール

かわいいアイコンですね。ラマのアイコンです。
上記のURLにアクセスしてダウンロードをクリックして下さい。その後ダウンロードページに行きますので、ご自身のOSを選択してインストールをすすめてください。とくにログインはいりません。
OllamaSetup.exeのセットアップインストーラーからダウンロードをすすめてください。
ダウンロード完了しても特になにできるわけでないので完了したら次に進みます。
2.Powershellを開く
コマンドプロントないしPowershellを開きます。今回はPowershellで。スタートからpowershellと打ち込めば出てくるはずです。
試しにちゃんとOllamaがインストールできてるか見ましょう。以下のコマンドを入力してください。
ollama --version
このようにバージョンが出ればOKです。
3.コマンドを使ってモデルをダウンロードする
さぁここから実際に使うモデルをダウンロードしてきます。今回は軽量なGoogleのgemma2というモデルで行きます。
ここに行きgemma2を探します。今回は一番小さい2Bを選びます。
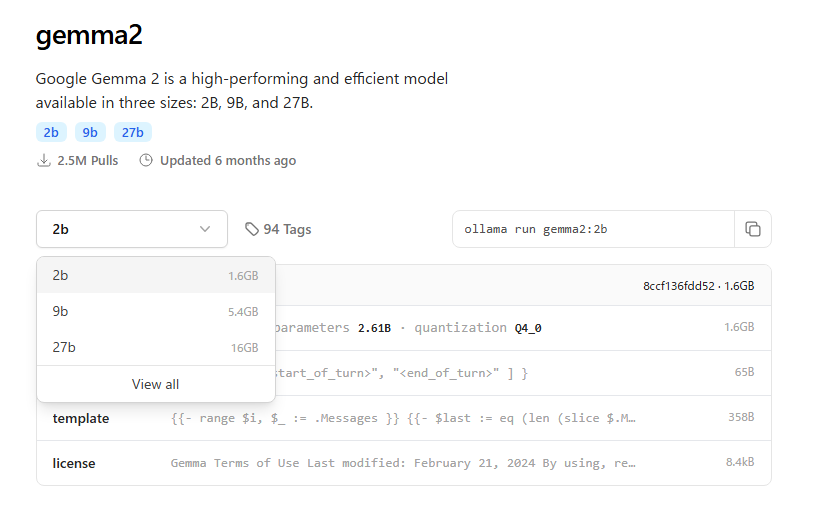
横にある
ollama run gemma2:2bをコピーしてPowerShellに打ち込みましょう。そうするとなんかダウンロード始まると思います。
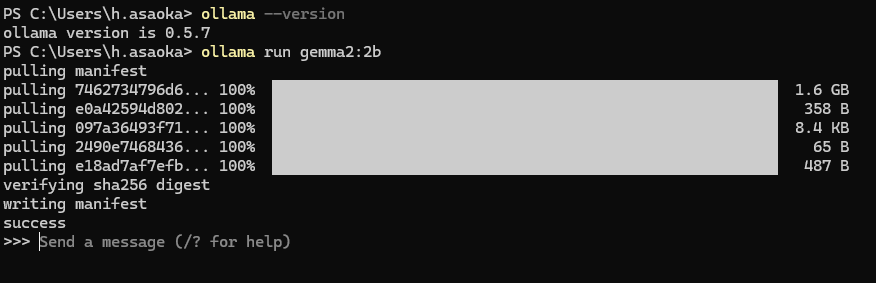
こうなれば完成です。実はこれでもう使えます!ではここに何か打ちましょう。
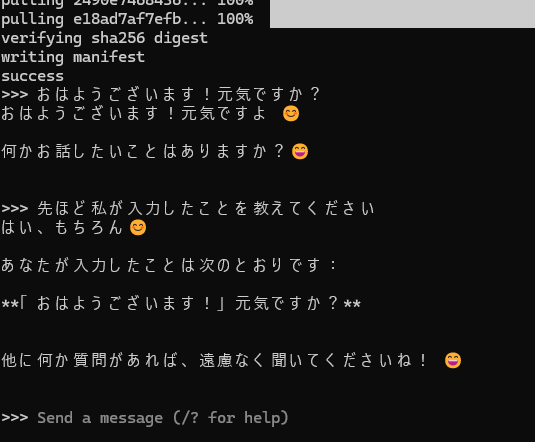
この通りです。日本語で会話できています。2Bであればノートパソコンでも比較的サクサクに動くと思います。会話をやめたい時は「Ctrl+D」をターミナル上で打てば止まります。また起動したい時はまた「ollama run gemma2:2b」を打てばいいです。2回目からはダウンロードされてれば、すぐに始まります。

4.ダウンロードされたモデルを見る
モデルは何個もダウンロードできます。ただし容量を食うので必要なければ削除をしてください。まずは一覧の見方です。
ollama list
こんな感じで
deepseek-r1:1.5b
gemma2:9b
gemma2:2b
の三つが入っていることがわかります。
5.ダウンロードしたモデルを削除する
ではgemma2:9bがいらない場合です。
ollama rm gemma2:9b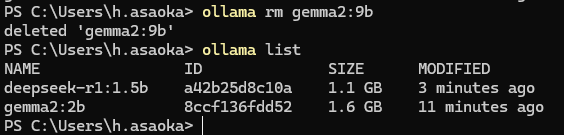
deletedと出ればOkです。もう一回listしてみて確認するとちゃんと9Bが消えてますね。
こんな感じで好きなモデルを選んでダウンロードしたり消したりしながら利用することができます。
ローカルLLMをRoo-codeと連帯させてみる
ではRoo-codeの利用するモデルにこのローカルLLMを使ってみましょう。実現できれば無料でAIエージェント使い放題です!(電気代はかかるけど)
さきほどのollama run ~をしてチャットできる状態にしておきましょう。今回は「gemma2:2b」で行きます。ollama run gemma2:2bをして会話できる状態にしておきましょう。
1.IDEを開いてRoo-Codeを開く。
基本的にはClineも一緒です。API ProviderをOllamaにすると今ダウンロードされてるモデルがでるので選べば勝手にModel IDに入力されます。Base URLは空欄でもデフォルトでlocalhost:11434が入るので特に入力不要です。これだけです!あとはRoo-Codeを使いましょう。
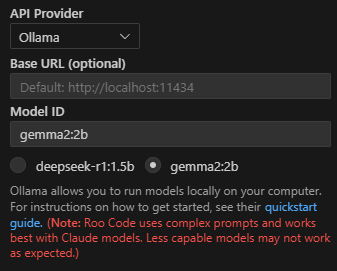
実際やってみます。
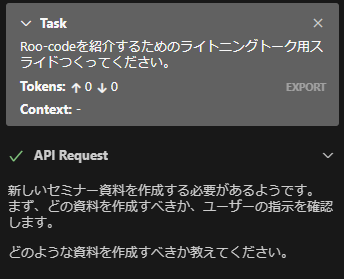
な、、、なんとかうごきました。かなり遅いです。しかも計量モデルなので意図をくみ取るのは難しそうですね。これは完全にPCスペックに左右されますので、いいPCならもっと大きな精度の高いものを簡単に作れます。
話題のDeepSeekの14B以上だと精度的にはやっといいかな!という感じなのでそれぐらいが最低でもサクサク動くPCがないとという感じです。そうなると普通にGemini 2.0 flash APIのとかが早くて安くて程よく精度もありとなってしまいます。
なのでまだ現状だとなんだかんだ
・AWS BedrockでClaude Sonnet
・AzureでGPT系統
・GCP(Vertex AI)でGeminiなどを使う
が精度もよくレスポンスもよく無難という感じです。
まとめ
今後さらに精度はあがってくるとより現実的になると思います。これができるとインターネットと閉鎖した環境での利用が可能になるためより選択肢も増えます。今後これが全PCで可能になる時代もくるのもそんなに時間がかからないのかなと思われます。


資料
ダウンロード
マスタデータのメンテナンスに関わる機能をまとめたSaaS「SMOOZ」
SMOOZはリレーショナルデータベースの課題を解決するサービスです。
オンラインデモで気軽に試すことが可能です。