
最終更新日: 2025年7月2日
2023年は様々な生成AIがでてきて、そろそろ情報の速度と量の多さの過多で話題を追うだけで疲れる、情報過多な「情報疲れ」をしている人もおおいのではないのでしょうか。
最近ビジネス系がらみでRAG(ラグ)検索拡張生成というワードが出始めてきました。今回はこのRAGについて解説します。
この記事でわかること
・RAG(Retrieval-Augmented Generation)の概要と仕組み
・RAG導入の課題と利用者の心理的影響
あわせて読みたい注目記事

RAG(ラグ)とは?
RAGとはRetrieval-Augmented Generation(リトリーバル オーグメンテッド ジェネレーション)の略です。
大規模言語モデル(LLM)による生成に、外部の独自の情報を組み合わせることで、回答精度を向上させる技術のことです。
検索拡張生成とも日本語で表記されます。読み方はいろいろな方を聞いていると「ラグ」とよばれることが多そうです。
Retrieval(リトリーバル):検索
Augmented(オーグメンテッド):拡張(増強)
Generation(ジェネレーション):生成
名の通り検索を使って生成を拡張しよう。というものです。
その結果、企業固有の情報を回答してくれます。これはハルシネーションリスクの解消を狙うものです。
ちなみに混同しやすい言葉に
・ファインチューニング
・エンベディング
・構造化
がありますがこれを一言で概念的に説明するなら、
・ファインチューニング
→生成AI自体を独自の回答に適した状態に学習させる
・エンベディング
→データ自体を生成AIが読みやすいような状態に最適化する(ベクトル化)
・構造化
→データを一定の規則や形式に従って生成AIが理解しやすいように整理
言葉として使用するのであれば
「ファインチューニングして、そのうえでデータをエンベディングし、構造化もしたうえでRAGで回答精度を高める」
といった言い回しが適切な表現になると思います。
RAGとは何をするの?
生成AIは事前に提供企業が学習させたデータやネット上の内容をもとに回答します。
そのため、普遍的な内容においては回答精度は高いです。でも、専門的な内容は弱くなります。
その対策として、例えば具体的には、RAGは社内の就業規則などを事前にセットすることで、回答するときにその内容を参照してから回答するというものです。
イメージとしては「生成AIのためのマニュアルを提供してあげる」ような感じです。
コールセンターで対応するときに人が対応するときもマニュアルを参考に回答すると思いますが、それを生成AIにもさせてあげようという感じです。
そうすることで、企業独自の情報だったりを回答させることができます。その結果、その企業にの人が回答するかのような精度を得られる可能性があります。
じゃあどうやるの?
まずは回答する生成AIです。
基本的には生成AIのAPIを使って作るので、一般的にはプログラム開発が必要です。今のところGPTなどがよく使われます。
チャットボット自体は、独自のチャットボットを開発したりslackなどの既存チャットを利用するケースです。そうなってくるとシステム構築費用が掛かります。
そこで一番簡単なのはOpen AIのGPT4のGPTsを使うことです。
Proプランに加入していればGUIで資料を上げるだけでRAGに近しいことは再現できます。
ただし、これでは業務セキュリティ性はもちろん、有料プランに全員加入してないといけないです。そもそも回答精度も業務仕様に足るレベルではありません。
※追記2024.05.15
Open AIからGPT-4o(ジーピーティーフォーオー)が発表されました。その発表の中でGPTsを無料ユーザーにも提供開始を発表していました。そのため無料で開始することはできますが、フロー処理などのオリジナルな複雑な処理は以前できない状況です。

Difyが熱い
「Dify」ここ数日賑わせています。簡単に言うと上記のようなチャットbotを開発できるノーコードツールです。しかも無料でかなりの利用が可能です。さらには商用化が可能です。
ただしチャットボットからDifyのロゴを消すには商用ライセンスが必要です。そのため、社内利用をするケースは利用価値があります。

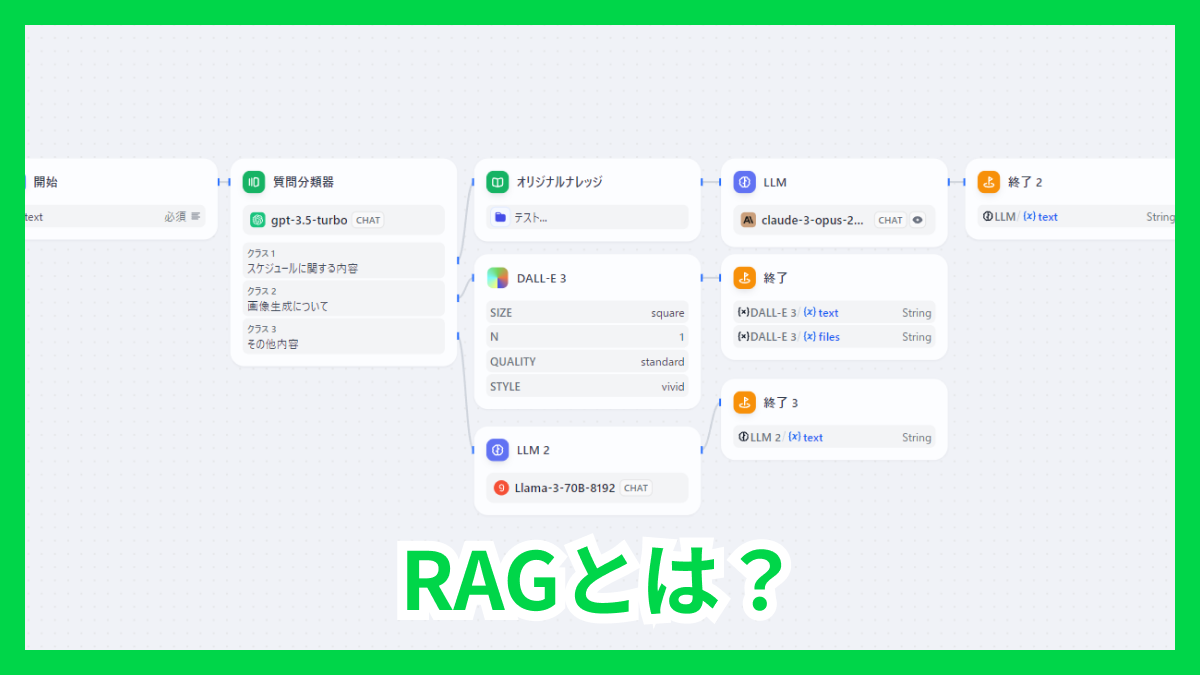
例えばこのような形で、これはDifyの画面ですがスケジュールに関する質問はナレッジを介して、その他質問は分岐をさせるような感じです。
例えばこのスケジュールを社内に関することにしたり、事業部に関することなどにしてナレッジを分けることでナレッジの読み込みを短縮して最適化することができたりすることができると思います。

RAGですが、それでも精度が…
ここまで説明してきましたが回答精度が上がるといってもやはり限界があります。
以下は過去に香川県三豊市がゴミ出しの案内に生成をAIを活用した事例があります。
https://www.itmedia.co.jp/news/articles/2312/15/news158.html
正答率94%。これってかなり高い数値です。
記事からはわかりませんが、もちろん単にRAGだけで何としたわけでなく、ファインチューニングしたうえで、エンベディングしてRAGで回答を求めた可能性がありますが、RAGサービスを提供する企業でも70%などが一般的です。
実際、記事内にも一問一答形式だと6割程度。対話型形式にして向上したという内容が記載されています。
なぜこれを断念したのか。
これは記事内にも関係者のインタービューによる理由がありますが、個人的推測を踏まえると、AI=機械 ととらえる以上回答率100%を求めるからではないかなと思います。
例えば、人だととらえてもし新人がマニュアル見ながら94%答えてくれたら助かると感じるはずです。
さらに、人でもAIのハルシネーションのような間違いを起こすことがあります。
でも、それがAIが機械である前提であるとどうでしょう。
間違えたときに、100%でないと責任の所在を追及できないため、踏み切れないといったところもあると思います。機械相手に厳しくなってしまうという心理が働いているかと思います。
また、一般消費者という責任問題を逃れることのできない対象への提供という点もあると思います。
利用者側の心理の影響か
さらには、利用者側の心理も重要です。
例えば、コールセンターで対人であれば、あまり適当なことは聞けないという心理的制約が発生すると思います。
ただそれが機械、AIだとしたらどうでしょうか。機械だし、わざと難しいことを聞いてみよう。といった心理が働きます。
その結果、ハルシネーションが起きやすくなる可能性もありえます。
そうなってくるとサービス提供する側もなかなか導入に踏み切れないといった心理状態になりえます。
まとめ
上記のようなケースは、抽象的な内容への回答精度の向上と、あえて非回答する判断力。そして、利用方法と間違えたときの責任についての解消方法が確立されれば利用シーンは増えていくと思います。
ただ、RAGは生成AIの活用方法の一つにすぎません。
今後生成AIの活用方法がいろいろ出てくるとおもますので、その一つの方法として覚えておくのがいいのかもしれません。
なお、当社でも生成AIに関して開発も進めています。お気軽にフォームよりお問合せください。



資料
ダウンロード
マスタデータのメンテナンスに関わる機能をまとめたSaaS「SMOOZ」
SMOOZはリレーショナルデータベースの課題を解決するサービスです。
オンラインデモで気軽に試すことが可能です。
[mwai_chatbot id=”smooz”]